
L’observabilité des microservices est essentielle au suivi et à l’amélioration continue. Des métriques, ou indicateurs peuvent s’adresser aux métiers, aux architectes, aux techniciens ou aux développeurs afin de prendre des décisions de manière rationnelle. Santé, disponibilité, performance, saturation, taux d’erreur, latence, ou encore données métiers : elles servent de base au déclenchement des alertes et à l’anticipation de certains évènements.
Pour mettre en place l’observabilité dans vos microservices, il faut les instrumenter. Pour cela, il existe différents patterns, mais l’objectif demeure le même.
Après avoir défini les métriques que vous souhaitez observer, il faudra définir la stratégie optimale pour instrumenter votre code afin de minimiser l’impact que pourrait avoir la mesure sur les performances de vos microservices (runtime overhead). En effet, les données clés de vos applications sont parfois uniquement mesurables au runtime et modifier le code source pour réaliser des mesures et mettre les résultats en mémoire pourrait alourdir l’application ou encore rompre avec le principe d’application sans état préconisé en conception cloud-native.
Pour remédier à ce problème, deux stratégies sont souvent privilégiées :


Très tôt dans le développement de BillingLabs, il nous est apparu indispensable de pouvoir déterminer les performances de la solution. Ainsi, ils nous étaient possible de détecter des développements qui dégradaient les performances et de les corriger. Ajouter à cela, nous pouvions ajouter des tests d’acceptance afin de s’assurer de la qualité du livrable. Nous avons opté pour le développement de notre propre solution. Pour les microservices qui exécutent des opérations courtes ou atomiques (par exemple, un calcul de facturation dans un batch) nous avons implémenté la stratégie Push : les workers qui ont la charge d’exécuter des opérations dans notre chaîne de facturations génèrent à chaque exécution un rapport au format JSON qui est poussé de manière asynchrone dans une base de données MongoDB. Ces rapports sont ensuite agrégés et exposés par des « exporters » qui sont scrapés régulièrement par Prometheus. Ainsi, nous conservons une traçabilité fine de chaque exécution, non agrégée et bien située dans le temps et ce même si le worker s’arrête au bout de quelques millisecondes. A l’inverse, les services type API REST n’ont pas les mêmes exigences en termes d’observabilité, ils n’ont pas le même cycle de vie que les workers : on peut se permettre de faire des mesures agrégées et moins fréquentes, par exemple pour compter le nombre de requêtes entrantes. Dans ce cas, nous utilisons la librairie client de Prometheus pour instrumenter nos APIs. La libraire en question permet de mettre en place des compteurs et gauges dans le code qui sont automatiquement exposés sur un endpoint HTTP, lequel sera régulièrement scrapé par le serveur Prometheus, qui est chargé de la persistance de ces données.
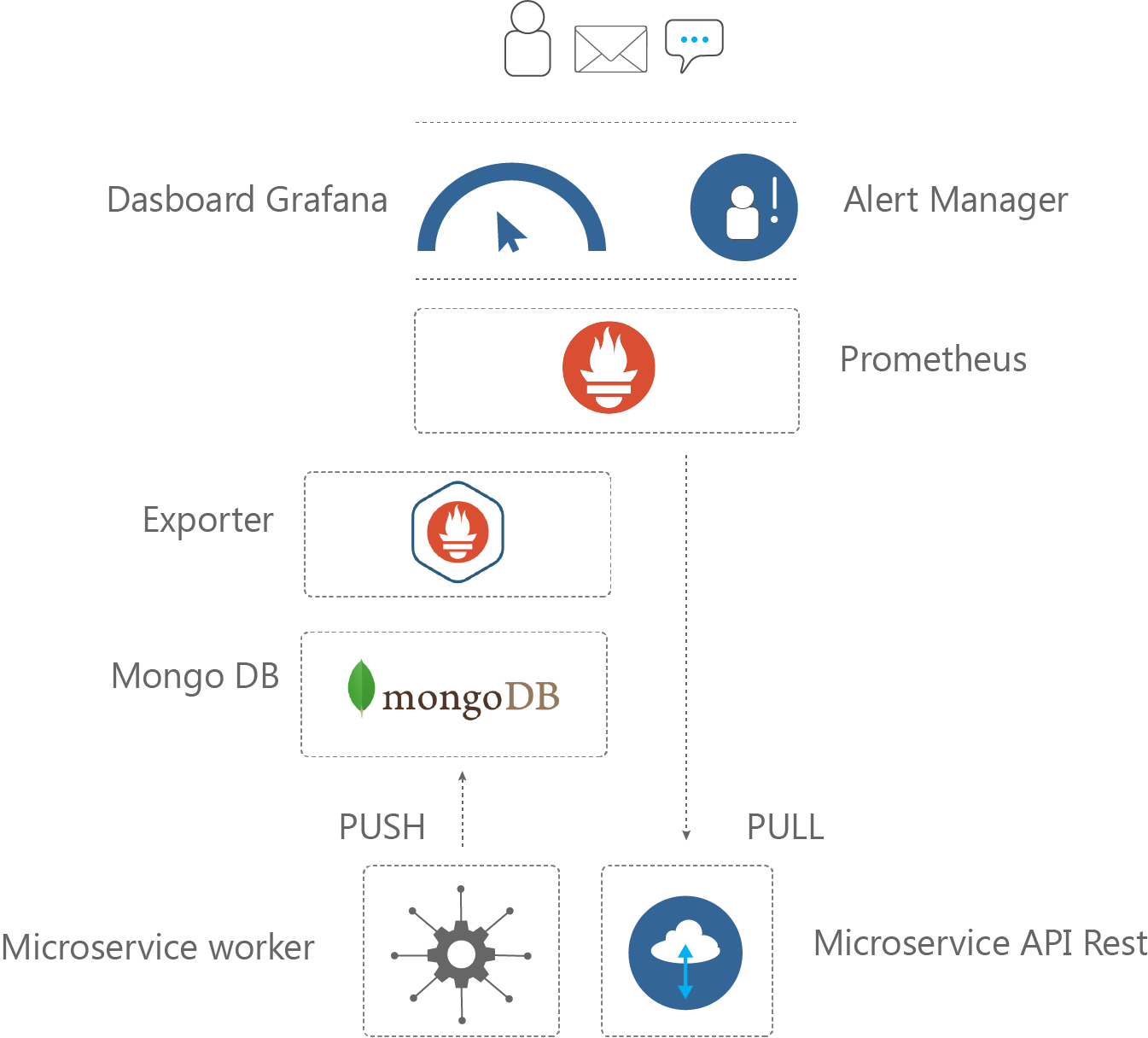
Figure 7 – Exemple de collecte de métriques et de leur exploitation à l’aide du duo Prometheus/Grafana
En mettant en place des indicateurs de performance comme le throughput de chaque worker, nous sommes parvenus à identifier les goulets d’étranglements de nos microservices. Nous avons pu travailler à l’amélioration des performances de ces derniers mais aussi prévoir un scaling horizontal des instances des microservices plus lents pour avoir un throughput réparti homogènement dans notre chaîne de billing.
D’autre part, l’outil Grafana nous permet de visualiser l’ensemble des métriques de nos services de manière très graphique, et également de lever des alertes basées sur des indicateurs techniques ou métiers, qui nous servent de base pour améliorer nos services.