
Dans une architecture microservice, les flux couvrent souvent plusieurs microservices. Chaque service pouvant faire appel à plusieurs autres microservices, il est important de pouvoir suivre ces flux d’un microservice à un autre pour pouvoir diagnostiquer une application. Pour ce faire il est possible d’utiliser des jetons. Ces jetons sont passés dans les flux interservices, il est ainsi possible de rapidement diagnostiquer une panne dans un environnement microservices. Les implémentations peuvent alors prendre la forme suivante :
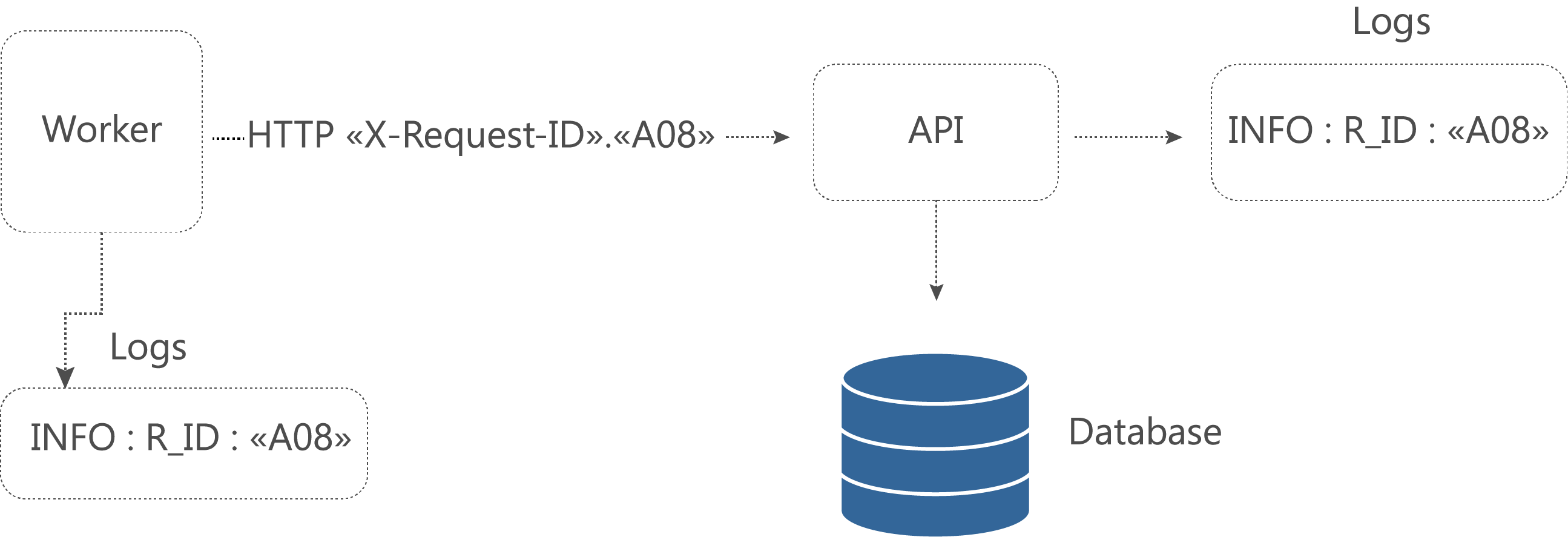
Figure 8 – Tracing de niveau 1 permettant de suivre une requête ainsi que son traitement
Il est aussi possible d’avoir plusieurs niveaux. Un identifiant pour le flux, un identifiant pour chaque requête lors du flux :

Figure 9 – Tracing de niveau 2 permettant d’obtenir les détails dans le cas d’une requête complexe


Pour les microservices de BillingLabs, nous avons implémenté la stratégie du « request-id » pour chaque appel http. De plus BillingLabs utilise un orchestrateur de flux « ChainFlow ». Cet orchestrateur génère plusieurs identifiants. Le « workflow_id » pour chaque instance du workflow. Le « step_id » pour chaque étape du workflow. Ces informations sont enregistrées dans une base de données NoSQL à chaque entrée et sortie de microservice.
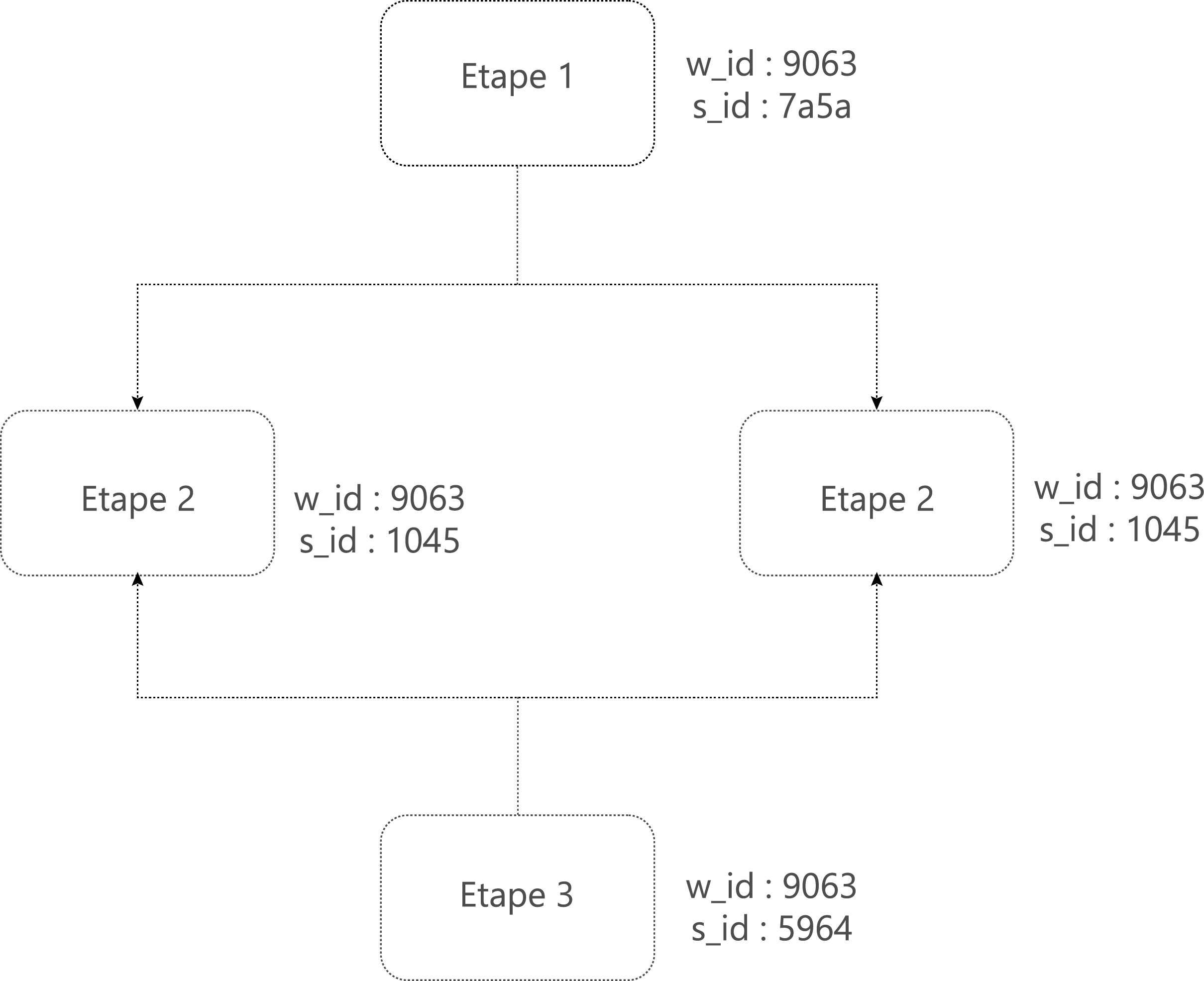
Figure 10 – L’usage d’identifiants uniques permettant de suivre le traitement
A l’aide des « ChainFlows » stockés en base de données et des « request-id », nous sommes capables de regrouper et visualiser l’exécution des flux à travers de nombreux microservices. En combinant ces informations avec l’aide d’une instance Sentry (solution permettant de collecter, regrouper et analyser des logs), cela nous permet de rapidement diagnostiquer une panne dans un environnement distribué.