
Le pattern « CQRS » (pour « Command and Query Responsibility Segregation ») consiste à séparer les responsabilités en matière de commande et de requête en séparant les opérations de lecture et d’écriture au sein d’une base de données.
En général, le même modèle de données est utilisé dans le cadre de la lecture et de l’écriture. Cette approche est exacerbée lors d’opérations CRUD mais est simple à mettre en œuvre.
Dès que l’on s’oriente vers des applications plus complexes, cette approche comporte de nombreuses limites. Lorsque l’on va lire des données, un mapping conséquent peut être nécessaire. Dans le cadre d’une écriture, une logique métier complexe doit être mise en place pour valider les données avant toute insertion ou mise à jour. Le modèle risque de gagner en complexité.
Cette approche a donc plusieurs limites:
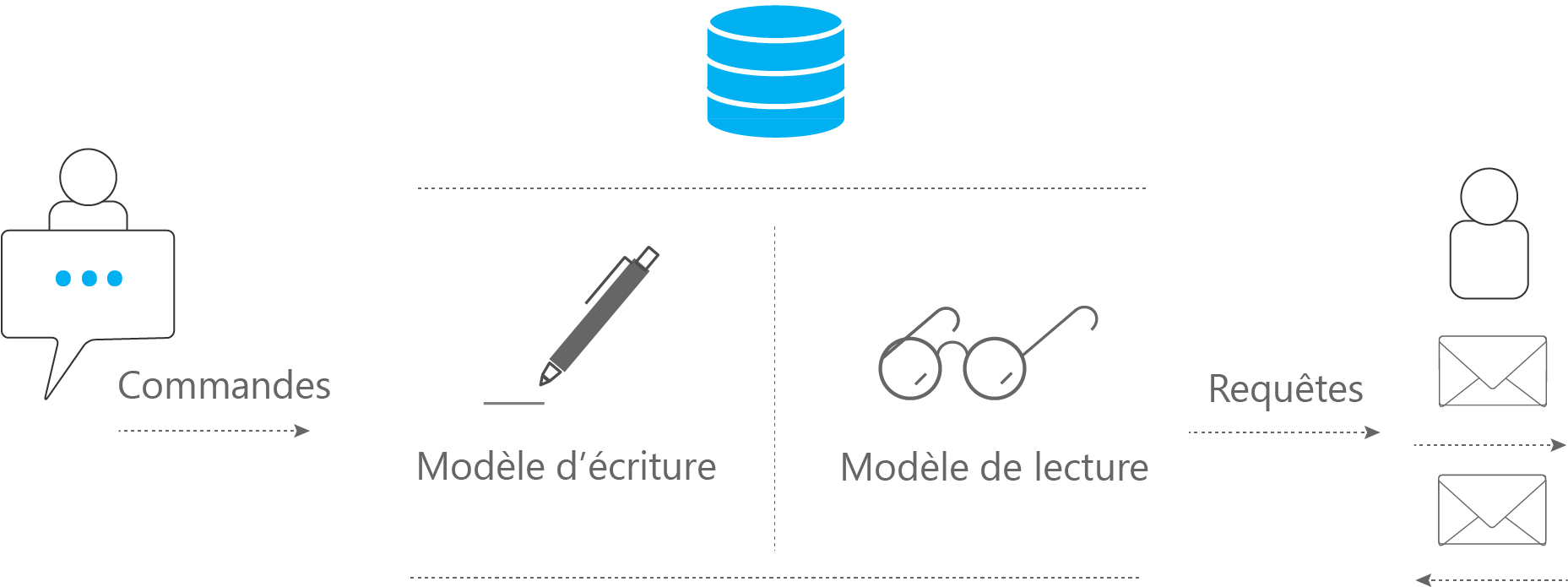
Le pattern CRQS essaye de résoudre ces difficultés en séparant les lectures et les écritures en différents modèles. On nommera alors « commandes » les actions correspondants à la mise à jour de données et « requêtes » les actions concernant la lecture.
Les commandes vont correspondre à une tâche complète, par exemple : « vente d’une voiture » au lieu de « définir le propriétaire d’une voiture à la valeur X » pour une mise à jour en CRUD. Les requêtes quant à elles, ne modifieront jamais la base de données et retourne des objets directement exploitables par le client.


Nous avons été amenés à réaliser une IHM de tracking afin de pouvoir suivre l’évolution de commandes dans le cadre du protocole Interop’Fibre. Le système existant était considéré comme une « boîte noire » par le client qui considérait que l’accent n’avait pas été mis sur le tracing. Nous reviendrons d’ailleurs sur ce pattern un peu plus tard dans ce livre blanc. La mise en place du tracing a permis de générer des entrées très précises à chaque création/modification d’une commande. Ces dernières étant stockées dans une base de données relationnelles de type SQL, il était facile et rapide de les insérer, mais plus compliquer de les exploiter. Nous avons concentré nos efforts sur la mise en place de vues matérialisées afin de faciliter la récupération du dernier état courant, l’historique des états d’une commande, mais aussi des agrégations sur les états afin d’obtenir une vision globale de l’ensemble des commandes. Ces vues permettent aussi de restreindre les données disponibles en fonction de rôles préétablis. On contrôle donc finement l’accès aux données confidentielles. Par ailleurs, les gains en performances apportées par les vues sont conséquents en précalculant les requêtes couteuses. Celles-ci sont ensuite proposées par une API REST qui va fournir efficacement les données à l’application web.